
前言
在上一篇文章中我为大家介绍了Simpe项目的一些背景知识以及如何使用有限状态机来实现词法解析,在本篇文章中我将会为大家介绍语法分析的相关内容,并且通过设计一门内部DSL语言来实现Simple语言的语法解析。
什么是语法解析
词法解析过后,字符串的代码会被解析生成一系列Token串,例如下面是代码let a = 'HelloWorld';的词法解析输出:
1 | [ |
在语法解析(Syntax Analysis)阶段,Simple解释器会根据定义的语法规则来分析单词之间的组合关系,从而输出一棵抽象语法树(Abstract Syntax Tree),这也就我们常听到的AST了。那么为什么说这棵语法树是抽象的呢?这是因为在语法解析阶段一些诸如分号和左右括号等用来组织代码用的token会被去掉,因此生成的语法树没有包含词法解析阶段生成的所有token信息,所以它是抽象的。在语法解析阶段,如果Simple解释器发现输入的Token字符串不能通过既定的语法规则来解析,就会抛出一个语法错误(Syntax Error),例如赋值语句没有右表达式的时候就会抛出Syntax Error。
从上面的描述可以看出,词法解析阶段的重点是分离单词,而语法解析阶段最重要的是根据既定的语法规则来组合单词。那么对于Simple解释器来说,它的语法规则又是什么呢?
Simple语言的语法
我们前面说到Simple语言其实是JavaScript的一个子集,所以Simple的语法也是JavaScript语法的一个子集。那么Simple的语法规则都有哪些呢?在进入到使用专业的术语表达Simple语法规则之前,我们可以先用中文来表达一下Simple的语法规则:
- 变量定义:let, const或者var后面接一个identifier,然后是可选的等号初始化表达式:
1
2
3let a;
// 或者
let a = 10; - if条件判断:if关键字后面加上由左右括号包裹起来的条件,条件可以是任意的表达式语句,接着会跟上花括号括起来的语句块。if语句块后面可以选择性地跟上另外一个else语句块或者else if语句块:
1
2
3
4
5if (isBoss) {
console.log('niu bi');
} else {
console.log('bu niu bi');
}; - while循环:while关键字后面加上由左右括号包裹起来的条件,条件可以是任意的表达式语句,接着是由花括号包裹起来的循环体:…
1
2
3while(isAlive) {
console.log('coding');
};
细心的你可能发现在上面的例子中所有语句都是以分号;结尾的,这是因为为了简化语法解析的流程,Simple解释器强制要求每个表达式都要以分号结尾,这样我们才可以将重点放在掌握语言的实现原理而不是拘泥于JavaScript灵活的语法规则上。
上面我们使用了最直白的中文表达了Simple语言的一小部分语法规则,在实际工程里面我们肯定不能这么干,我们一般会使用巴克斯范式(BNF)或者扩展巴克斯范式(EBNF)来定义编程语言的语法规则。
BNF
我们先来看一个变量定义的巴科斯范式例子: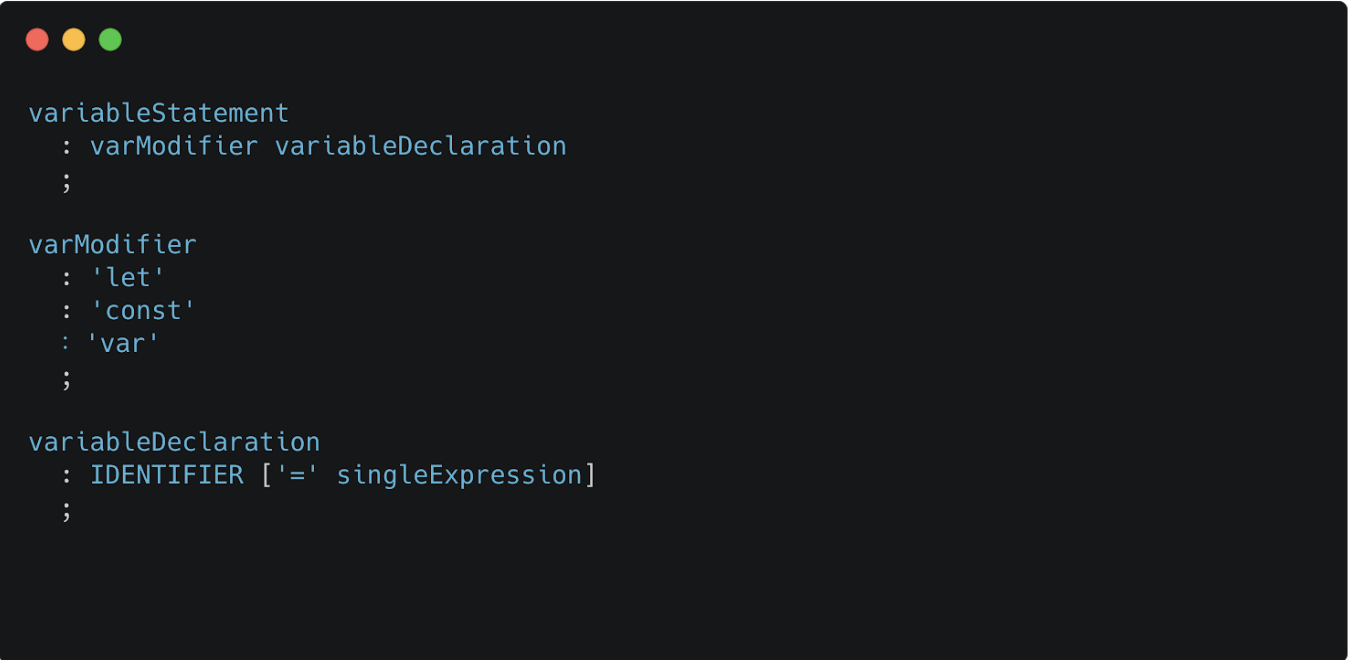
在上面的巴科斯范式中,每条规则都是由左右两部分组成的。在规则的左边是一个非终结符,而右边是终结符和非终结符的组合。非终结符表示这个符号还可以继续细分,例如varModifier这个非终结符可以被解析为let,const或var这三个字符的其中一个,而终结符表示这个符号不能继续细分了,它一般是一个字符串,例如if,while,(或者)等。无论是终结符还是非终结符我们都可以统一将其叫做模式(pattern)。
在BNF的规则中,除了模式符号,还有下面这些表示这些模式出现次数的符号,下面是一些我们在Simple语言实现中用到的符号:
| 符号 | 作用 |
|---|---|
| [pattern] | 是option的意思,它表示括号里的模式出现0次或者一次,例如变量初始化的时候后面的等号会出现零次或者1次,因为初始值是可选的 |
| pattern1 | pattern2 | 是or的意思,它表示模式1或者模式2被匹配,例如变量定义的时候可以使用let,const或者var |
| { pattern } | 是repeat的意思, 表示模式至少重复零次,例如if语句后面可以跟上0个或者多个else if |
要实现Simple语言上面这些规则就够用了,如果你想了解更多关于BNF或者EBNF的内容,可以自行查阅相关的资料。
如何实现语法解析
在我们编写完属于我们语言的BNF规则之后,可以使用Yacc或者Antlr等开源工具来将我们的BNF定义转化成词法解析和语法解析的客户端代码。在实现Simple语言的过程中,为了更好地学习语法解析的原理,我没有直接使用这些工具,而是通过编写一门灵活的用来定义语法规则的领域专用语言(DSL)来定义Simple语言的语法规则。可能很多同学不知道什么是DSL,不要着急,这就为大家解释什么是DSL。
DSL的定义
身为程序员,我相信大家都或多或少听说过DSL这个概念,即使你没听过,你也肯定用过。在了解DSL定义之前我们先来看一下都有哪些常用的DSL:
- HTML
- CSS
- XML
- JSX
- Markdown
- RegExp
- JQuery
- Gulp
…
我相信作为一个程序员特别是前端程序员,大家一定不会对上面的DSL感到陌生。DSL的全称是Domain-Specific Language,翻译过来就是领域特定语言,和JavaScrpt等通用编程语言(GPL - General-Purpose Language)最大的区别就是:DSL是为特定领域编写的,而GPL可以用来解决不同领域的问题。举个例子,HTML是一门DSL,因为它只能用来定义网页的结构。而JavaScript是一门GPL,因此它可以用来解决很多通用的问题,例如编写各式各样的客户端程序和服务端程序。正是由于DSL只需要关心当前领域的问题,所以它不需要图灵完备,这也意味着它可以更加接近人类的思维方式,让一些不是专门编写程序的人也可以参与到DSL的编写中(设计师也可以编写HTML代码)。
DSL的分类
DSL被分成了两大类,一类是内部DSL,一类是外部DSL。
内部DSL
内部DSL是建立在某个宿主语言(通常是一门GPL,例如JavaScript)之上的特殊DSL,它具有下面这些特点:
- 和宿主语言共享编译与调试等基础设施,对那些会使用宿主语言的开发者来说,使用该宿主语言编写的DSL的门槛会很低,而且内部DSL可以很容易就集成到宿主语言的应用里面去,它的使用方法就像引用一个外部依赖一样简单,宿主欢迎只需要安装就可以了。
- 它可以视为使用宿主语言对特定任务(特定领域)的一个封装,使用者可以很容易使用这层封装编写出可读性很高的代码。例如JQuery就是一门内部DSL,它里面封装了很多对页面DOM操作的函数,由于它的功能很有局限性,所以它可以封装出更加符合人们直觉的API,而且它编写的代码的可读性会比直接使用浏览器原生的native browser APIS要高很多。
下面是一个分别使用浏览器原生API和使用JQuery API来实现同样任务的例子: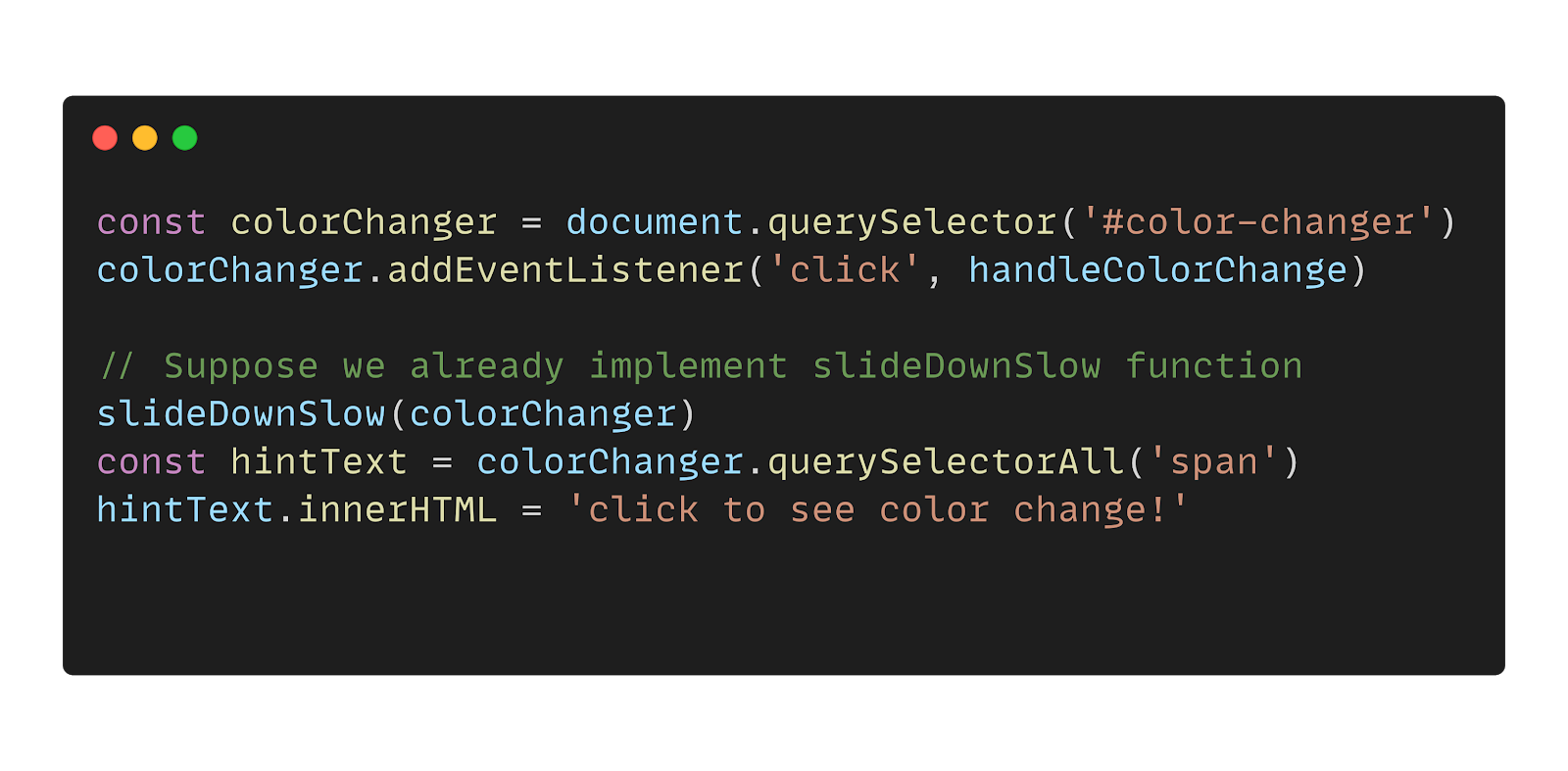

外部DSL
和内部DSL不同,外部DSL没有依赖的宿主环境,它是一门独立的语言,例如HTML和CSS等。因为外部DSL是完全独立的语言,所以它具有下面这些特点:
- 不能享用现有语言的编译和调试等工具,如有需要要自己实现,成本很高
- 如果你是语言的实现者,需要自己设计和实现一门全新的语言,对自己的要求很高。如果你是语言的学习者就需要学习一门新的语言,比内部DSL具有更高的学习成本。而且如果语言的设计者自身水平不够,他们弄出来的DSL一旦被用在了项目里面,后面可能会成为阻碍项目发展的一个大坑
- 同样也是由于外部DSL没有宿主语言环境的约束,所以它不会受任何现有语言的束缚,因此它可以针对当前需要解决的领域问题来定义更加灵活的语法规则,和内部DSL相比它有更小的来自于宿主语言的语言噪声
下面是一个外部DSL的例子 - Mustache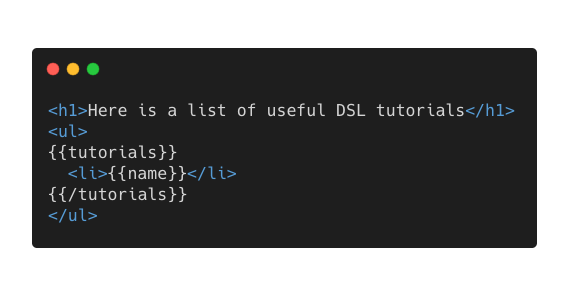
Simple语言的语法解析DSL
前面说到了内部DSL和外部DSL的一些特点和区别,由于我们的语法解析逻辑要和之前介绍的词法解析逻辑串联起来,所以我在这里就选择了宿主环境是TypeScript的内部DSL来实现
DSL的设计
如何从头开始设计一门内部DSL呢?我们需要从要解决的领域特定问题出发,对于Simple语言它就是:将Simple语言的BNF语法规则使用TypeScipt表达出来。在上面BNF的介绍中,我们知道BNF主要有三种规则:option,repeat和or。每个规则之间可以相互组合和嵌套,等等,互相组合和嵌套?你想到了什么JavaScript语法可以表达这种场景?没错就是函数的链式调用。
对于程序员来说最清晰的解释应该是直接看代码了,所以我们可以来看一下Simple语言语法解析的代码部分。和词法解析类似,Simple的语法规则放在lib/config/Parser这个文件中,下面是这个文件的示例内容:
1 | // rule函数会生成一个根据定义的语法规则解析Token串从而生成AST节点的Parser实例,这个函数会接收一个用来生成对应AST节点的AST类,所有的AST节点类定义都放在lib/ast/node这个文件夹下 |
上面就是Simple的if表达式定义了,由于使用了DSL进行封装,ifStatement的语法规则非常通俗易懂,而且十分灵活。试想一下假如我们突然要改变ifStatement的语法规则:不允许if后面加else if。要满足这个改变我们只需要将rule().separator(TOKEN_TYPE.ELSE).ast(ifStatement)这个规则去掉就可以了。接着就让我们深入到上面代码的各个函数和变量的定义中去:
rule函数
这个函数是一个用来生成对应AST节点Parser的工厂函数,它会接收一个AST节点的构造函数作为参数,然后返回一个对应的Parser类实例。
1 | // lib/ast/parser/rule |
Parser类
Parser类是整个Simple语法解析的核心。它通过函数链式调用的方法定义当前AST节点的语法规则,在语法解析阶段根据定义的语法规则消耗词法解析阶段生成的Token串,如果语法规则匹配它会生成对应AST节点,否则Token串的光标会重置为规则开始匹配的位置(回溯)从而让父节点的Parser实例使用下一个语法规则进行匹配,当父节点没有任何一个语法规则满足条件时,会抛出Syntax Error。下面是Parser类的各个函数的介绍:
| 方法 | 作用 |
|---|---|
| .separator(TOKEN) | 定义一个终结符语法规则,该终结符不会作为当前AST节点的子节点,例如if表达式的if字符串 |
| .token(TOKEN) | 定义一个终结符语法规则,该终结符会被作为当前AST节点的子节点,例如算术表达式中的运算符(+,-,*,/) |
| .option(parser) | 定义一个可选的非终结符规则,非终结符规则都是一个子Parser实例,例如上面if表达式定义中的else if子表达式 |
| .repeat(parser) | 定义一个出现0次或者多次的非终结符规则,例如数组里面的元素可能是0个或者多个 |
| .or(…parser | TOKEN) |
| .expression(parser, operatorsConfig) | 特殊的用来表示算术运算的规则 |
| .parse(tokenBuffer) | 这个函数会接收词法解析阶段生成的tokenBuffer串作为输入,然后使用当前Parser实例的语法规则来消耗TokenBuffer串的内容,如果有完全匹配就会根据当前Parser节点的AST构造函数生成对应的AST节点,否则会将TokenBuffer重置为当前节点规则开始匹配的起始位置(setCursor)然后返回到父级节点 |
AST节点类的定义
Simple语言所有的AST节点定义都放在lib/ast/node这个文件夹底下。对于每一种类型的AST节点,这个文件夹下都会有其对应的AST节点类。例如赋值表达式节点的定义是AssignmentExpression类,if语句的定义是IfStatement类等等。这些节点类都有一个统一的基类Node,Node定义了所有节点都会有的节点类型属性(type),节点生成规则create函数,以及当前节点在代码执行阶段的计算规则evaluate函数。下面是示例代码:
1 | // lib/ast/node/Node |
现在我们来看一下IfStatement这个AST节点类的定义
1 | class IfStatement extends Node { |
AST
介绍完Parser类和AST节点类后你现在就可以看懂lib/config/Parser的语法规则定义了,这个文件里面包含了Simple所有语法规则的定义,其中包括根节点的定义:
1 | // 列举了所有可能的statement |
最后就是将上一章的词法解析和语法解析串联起来,代码在lib/parser这个文件里面:
1 | // tokenBuffer是词法解析的结果 |
我们来看一下rootNode的具体内容,假如开发者写了以下的代码:
1 | let a = true; |
会生成下面的AST:
1 | { |
小结
在本篇文章中我介绍了什么是语法解析,以及给大家入门了领域专用语言的一些基本知识,最后讲解了Simple语言是如何利用内部DSL来实现其语法解析机制的。
在下一篇文章中我将会为大家介绍Simple语言的运行时是如何实现的,会包括闭包如何实现以及this绑定等内容,大家敬请期待!
个人技术动态
欢迎关注公众号进击的大葱一起学习成长


